示例
SQL任务
支持的数据源类型有
MYSQL
POSTGRES
HIVE
SPARK
CLICKHOUS
ORACLE
SQLSERVER
DB2
PRESTO
REDSHIFT
SQL类型分为
查询:针对select类型的查询,是有结果集返回的
非查询:针对update、delete、insert三种类型的操作,没有结果集返回的
以MYSQL 查询为例:

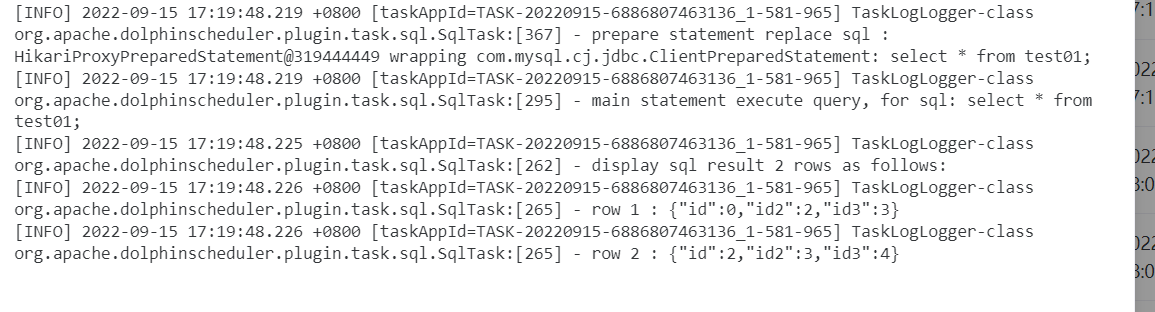
以MYSQL 非查询为例:

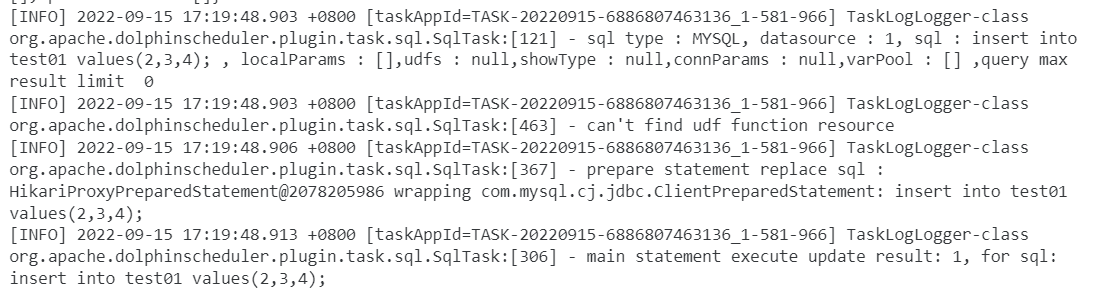
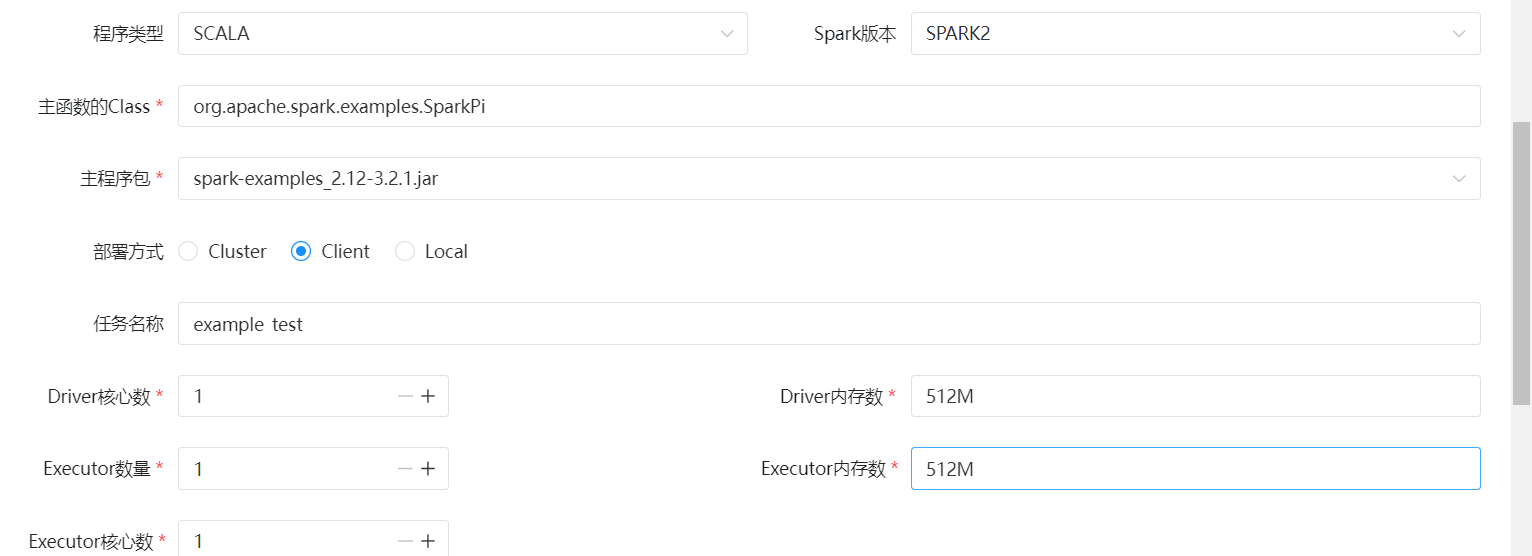
Spark任务
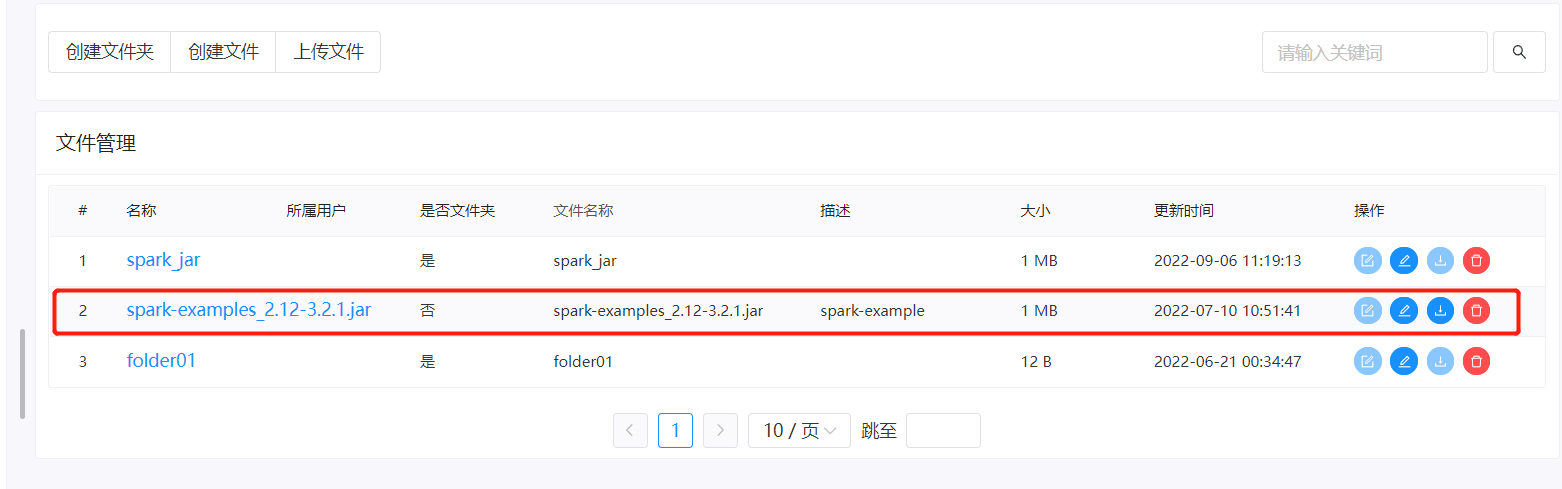
引用上传jar包
在资源-文件管理中上传jar包
将SPARK任务类型拖拽至右侧,示例配置如下:
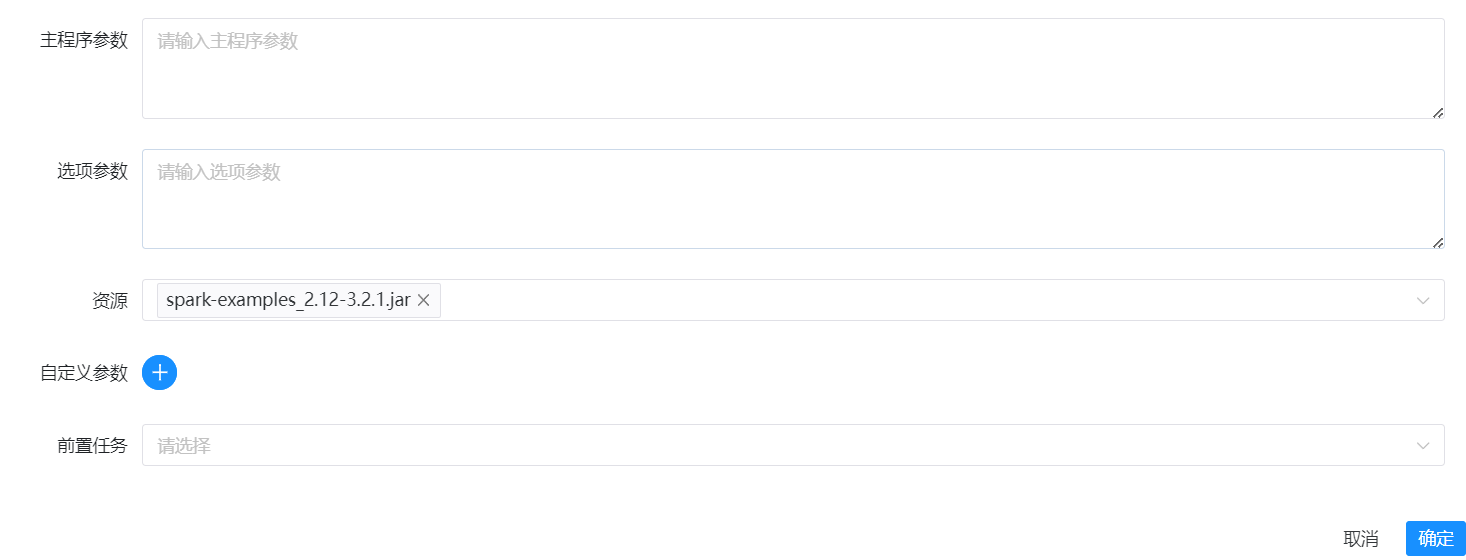
Shell任务
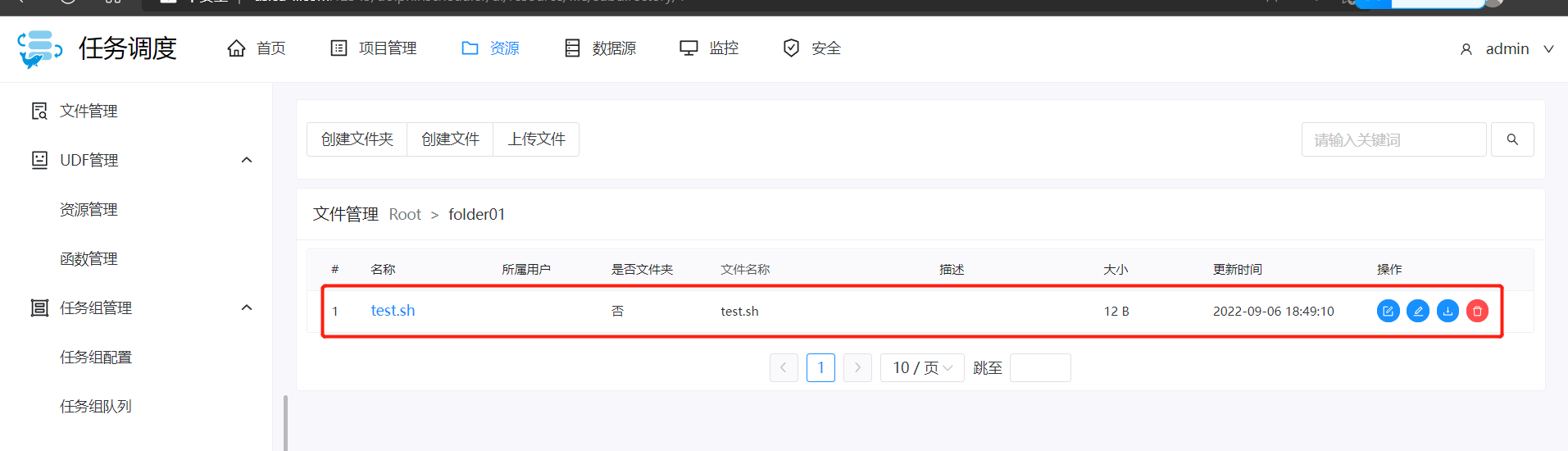
引用上传的shell脚本
上传shell脚本
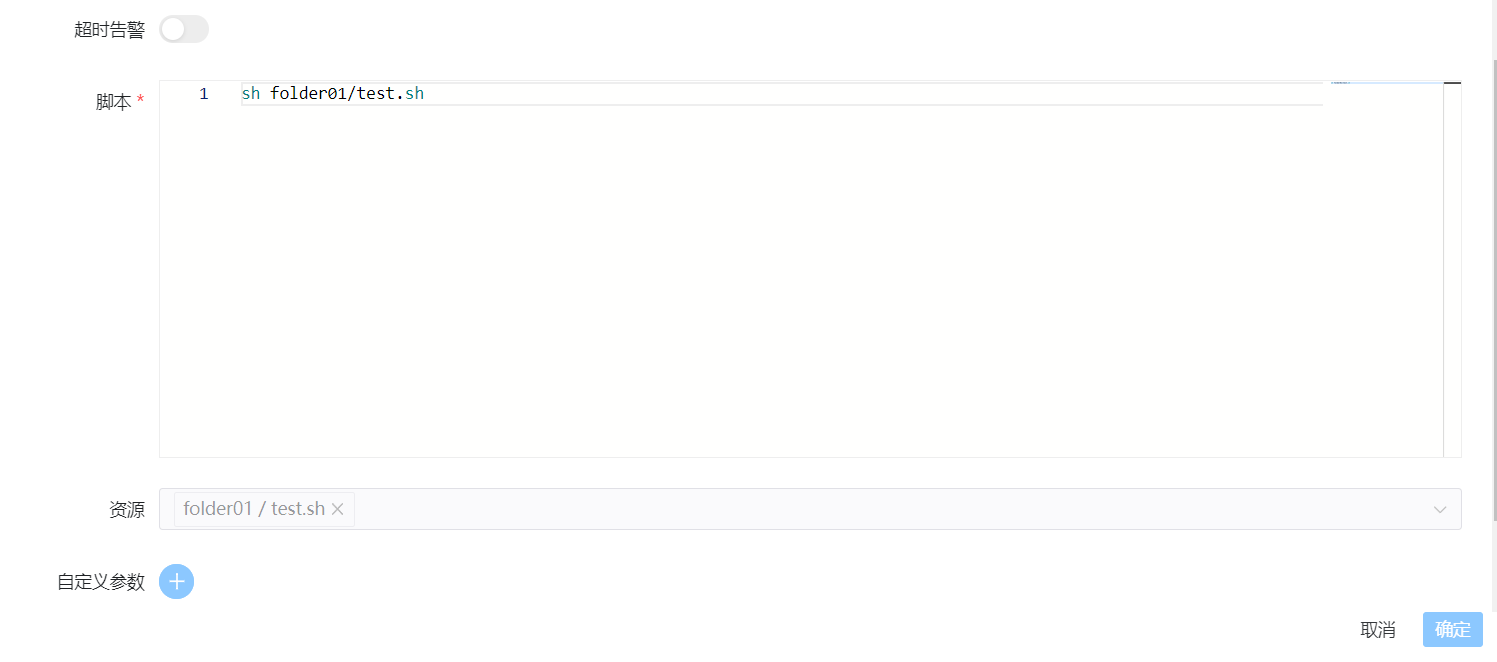
执行上传的shell 脚本,配置如下
子流程节点
子流程节点,就是把外部的某个工作流定义当做一个节点去执行。
示例中,"子流程测试-任务-1"为外部单独的工作流,在示例工作流中,为子流程节点。
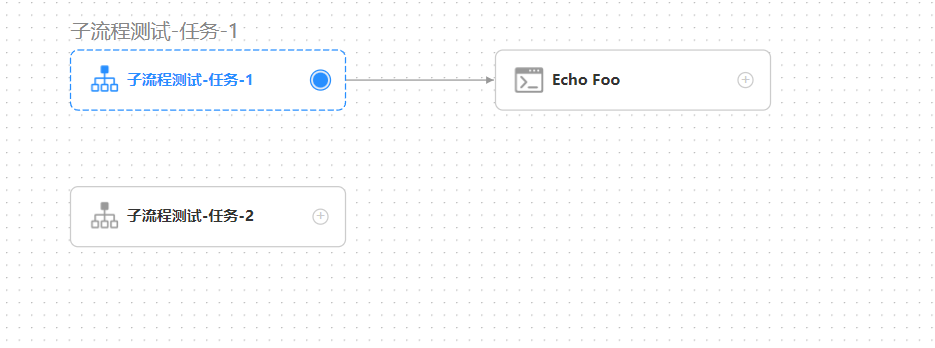
子流程测试-任务-1,工作流中可以包含多个节点。
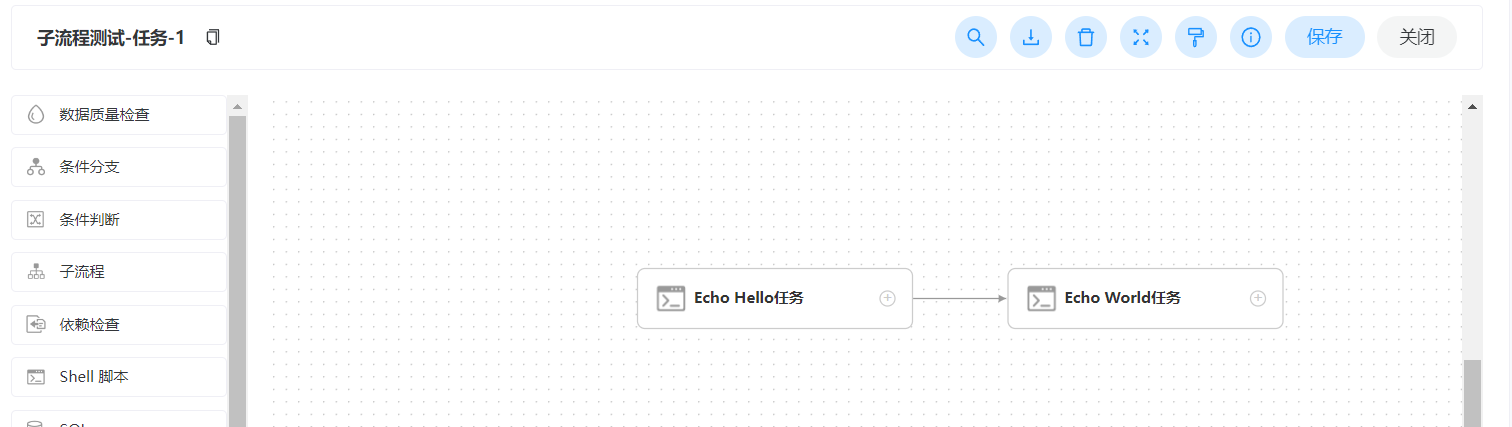
子流程测试-任务-2,工作流中也可以是单个节点。

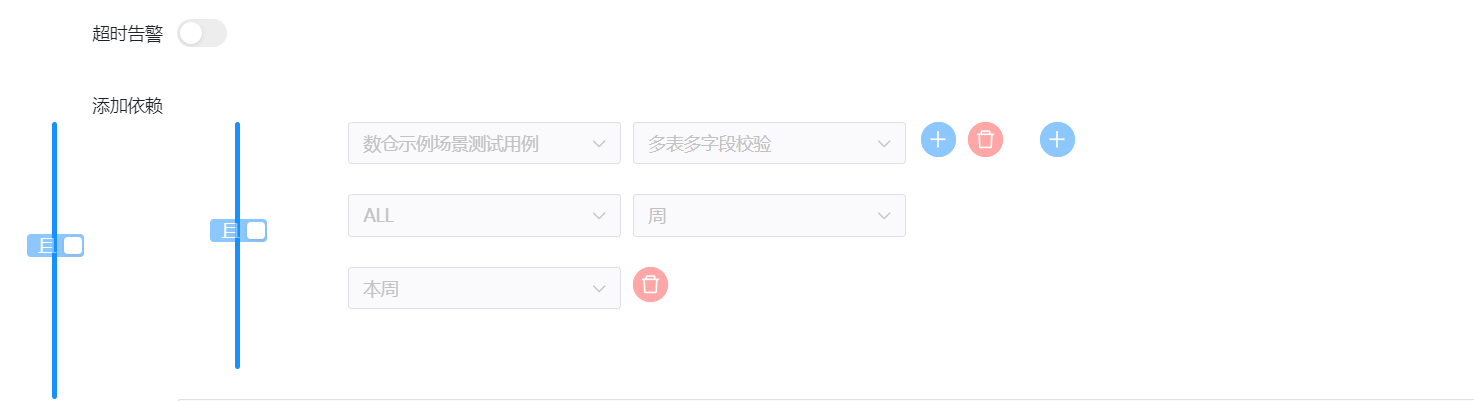
依赖检查节点
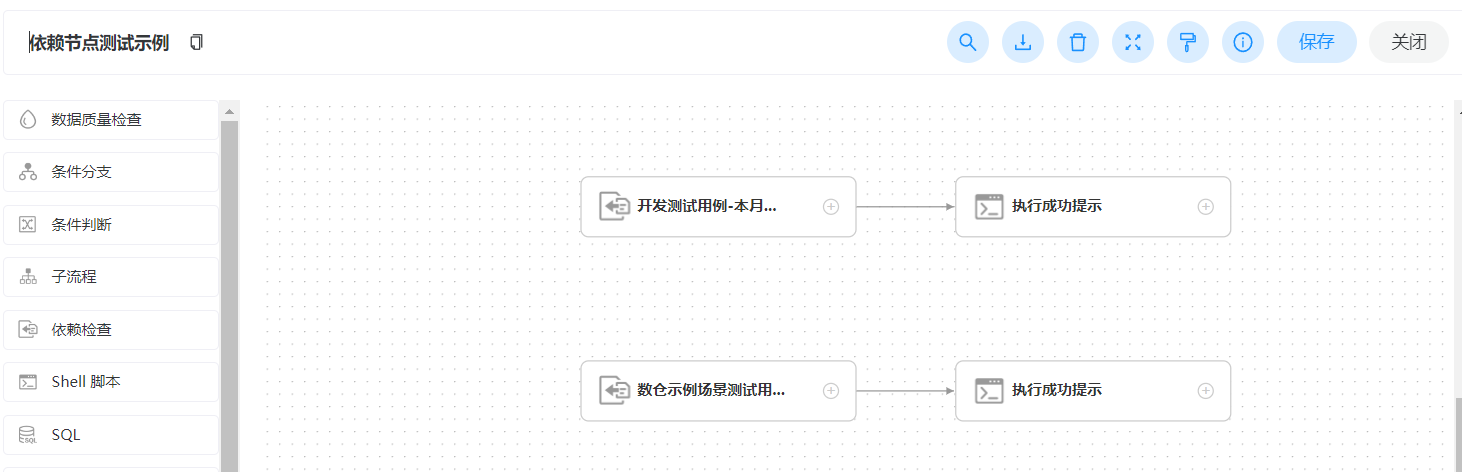
Dependent 节点,就是依赖检查节点。比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例。
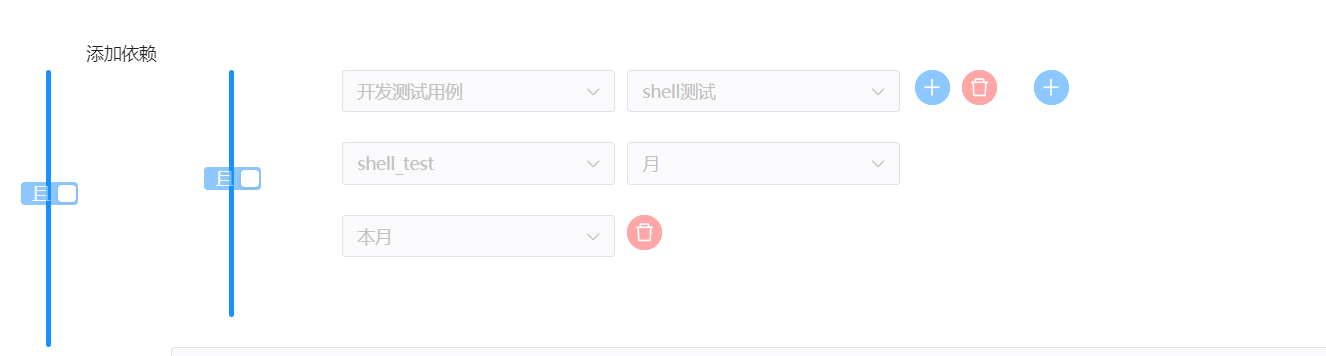
判断shell_test本月是否有执行成功的示例。
判断多表多字段校验本周是否有执行成功的示例。
DataX任务
前提
安装 DolphinScheduler 并配置 DataX。
测试表
源表 t5
CREATE TABLE `t5`(
`id_card` int,
`tran_time` string,
`name` string,
`cash` int
)
PARTITIONED BY (`ds` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION 'hdfs://bigdata01:9000/user/hive/warehouse/test.db/t5'
TBLPROPERTIES ('transient_lastDdlTime'='1627435885');
INSERT INTO t5 partition(ds='2020-09-21') values (1000, '2020-09-21 14:30:00', 'Tom', 100);
INSERT INTO t5c partition(ds='2020-09-20') values (1000, '2020-09-20 14:30:05', 'Tom', 50);
INSERT INTO t5 partition(ds='2020-09-20') values (1000, '2020-09-20 14:30:10', 'Tom', -25);
INSERT INTO t5 partition(ds='2020-09-21') values (1001, '2020-09-21 15:30:00', 'Jelly', 200);
INSERT INTO t5 partition(ds='2020-09-21') values (1001, '2020-09-21 15:30:05', 'Jelly', -50);
目标表 t6
CREATE TABLE `t6`(
`id_card` int,
`tran_time` string,
`name` string,
`cash` int
)
PARTITIONED BY (ds` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION 'hdfs://bigdata01:9000/user/hive/warehouse/test.db/t6'
TBLPROPERTIES ('transient_lastDdlTime'='1627435885');
DataX JSON
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/test.db/t5",
"defaultFS": "hdfs://bigdata01:9000",
"column": [
{
"index": "0",
"type": "INT"
},
{
"index": "1",
"type": "string"
},
{
"index": "2",
"type": "string"
},
{
"index": "3",
"type": "int"
}
],
"fileType": "ORC",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://bigdata01:9000",
"fileType": "orc",
"path": "/user/hive/warehouse/test.db/t6",
"fileName": "xxxx",
"column": [
{
"name": "id_card",
"type": "INT"
},
{
"name": "tran_time",
"type": "string"
},
{
"name": "name",
"type": "string"
},
{
"name": "cash",
"type": "string"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"compress":"NONE"
}
}
}
]
}
}
测试过程
在Hive创建表 t5、t6,并在t5中插入测试数据
创建工作流,名称:datax_test
创建任务,名称:hive_to_hive_test,选中【自定义模板】,填写上面的 JSON
上线工作流,并执行
查看工作流和任务实例状态
检查t6表中数据
参数传递
任务参数传递和替代符。
分区sql不能用动态参数
alter table employee add PARTITION ${ymd} values (${ymd}); -- 错误
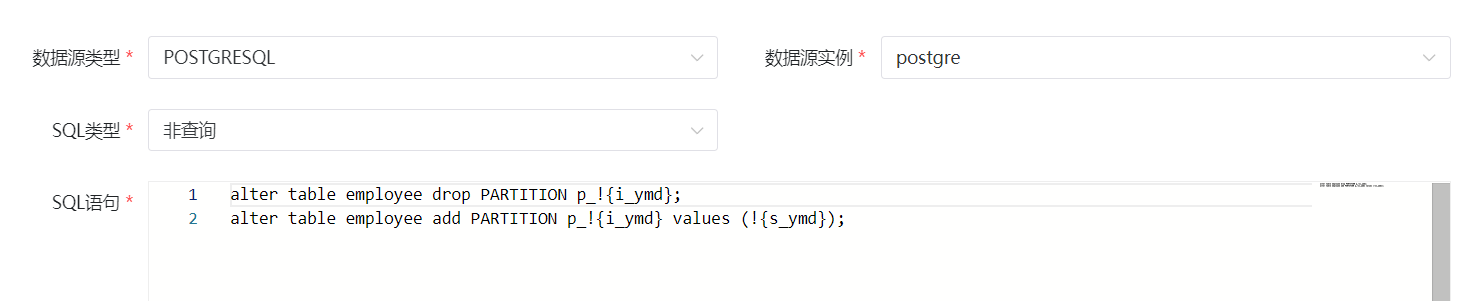
替代符生成SQL
alter table employeess add PARTITION p_!{i_ymd} values (!{s_ymd});
| 参数名 | 方向 | 类型 | 示例值 |
|---|---|---|---|
| i_ymd | IN | INTEGER | 20200808 |
| s_ymd | IN | VARCHAR | '2020-08-08' |
上游给下游传入参数
上游
select
cast(to_char(now(),'yyyymmdd') as int) as i_ymd,
to_char(now(),'''yyyy-mm-dd''') as s_ymd; -- 引号需要转义
| 参数名 | 方向 | 类型 | 示例值 |
|---|---|---|---|
| i_ymd | OUT | INTEGER | 20200808 |
| s_ymd | OUT | VARCHAR | '2020-08-08' |


下游
alter table employee drop PARTITION p_!{i_ymd};
alter table employee add PARTITION p_!{i_ymd} values (!{s_ymd});
内置参数
https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/built-in.html
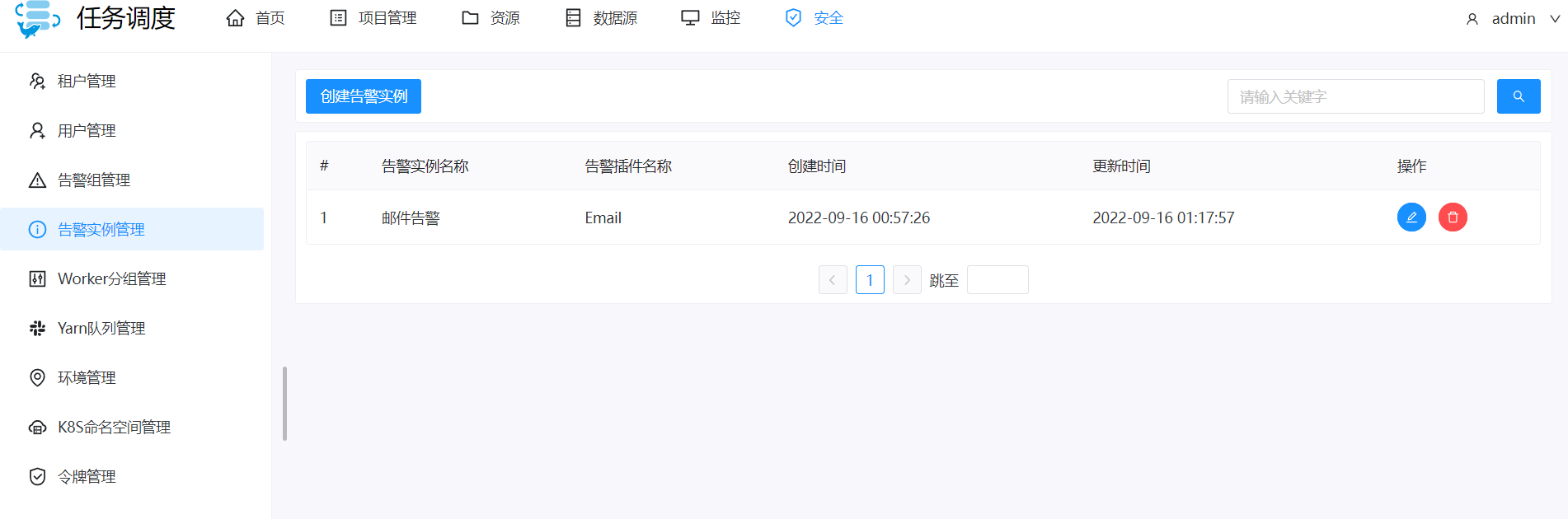
邮件告警
创建告警实例
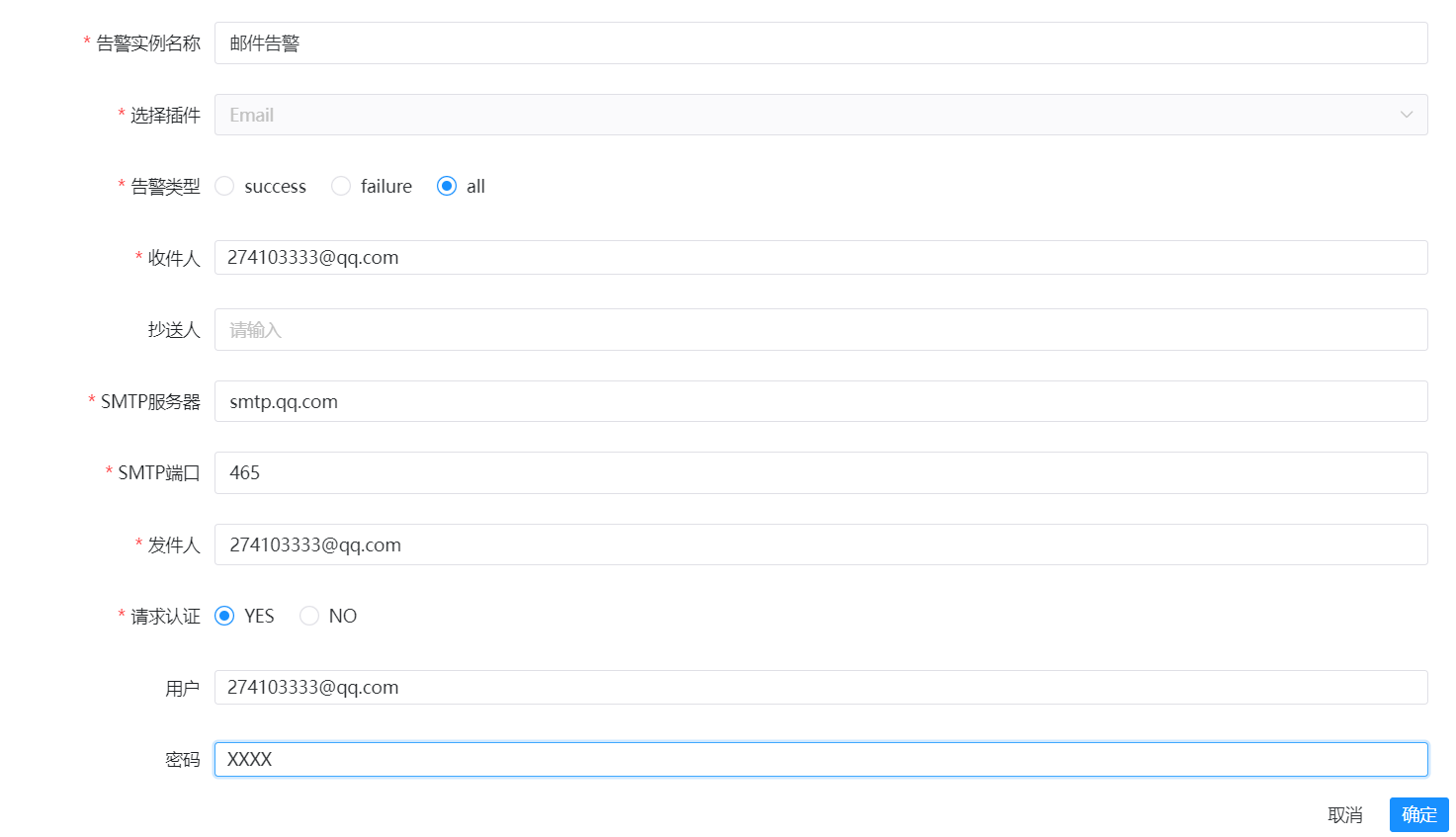
配置告警示例

运行shell测试工作流
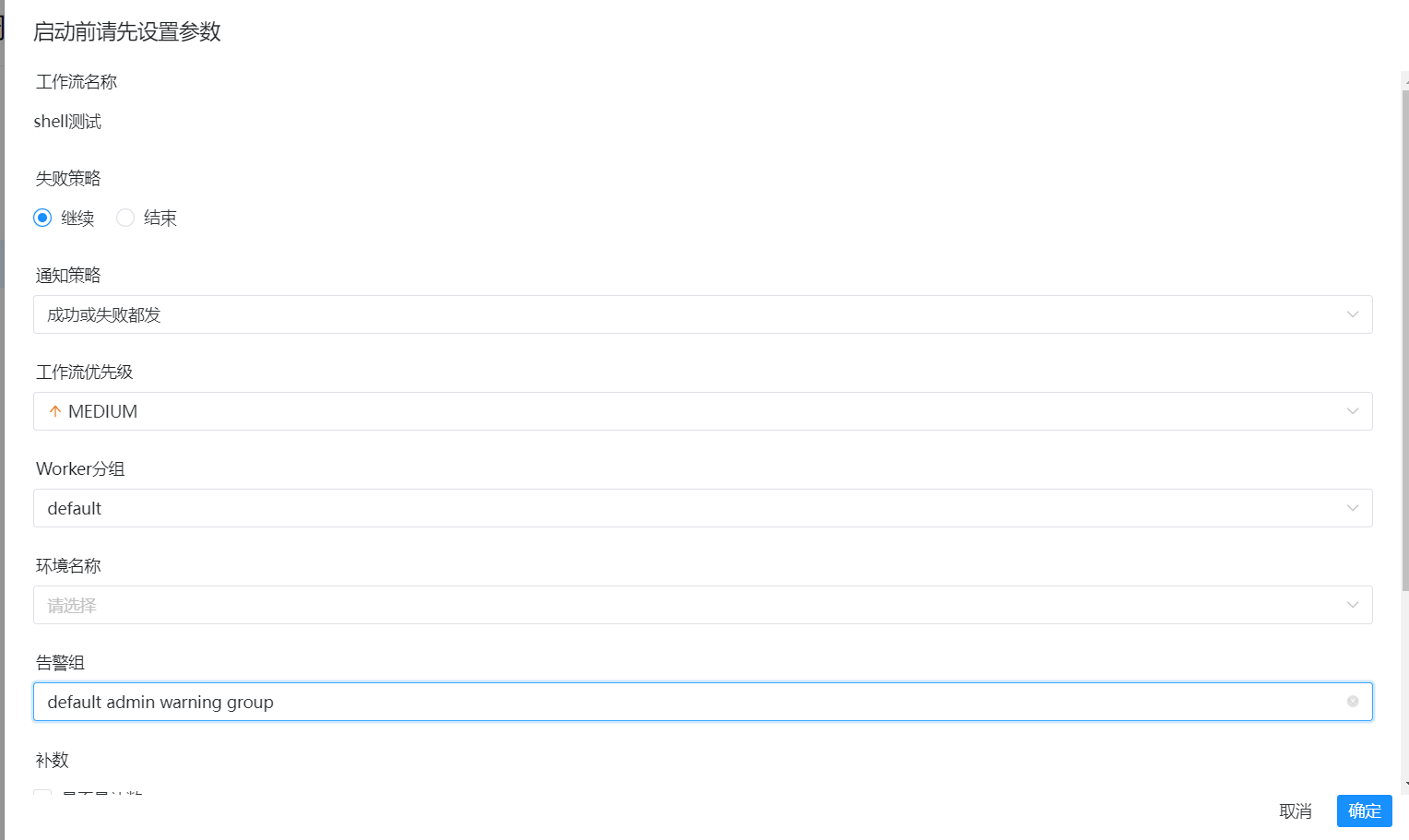
启动前的参数配置:
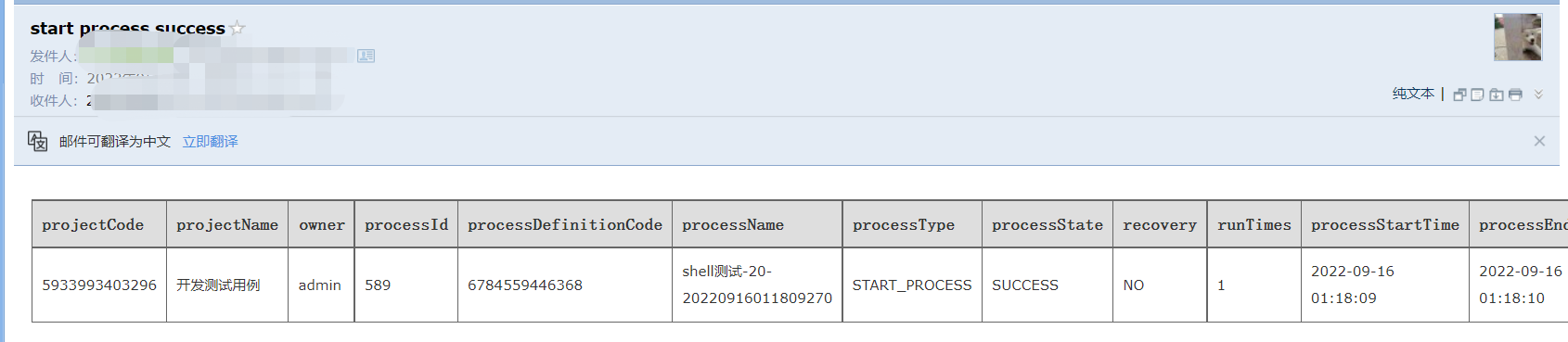
收到的邮件内容如下:
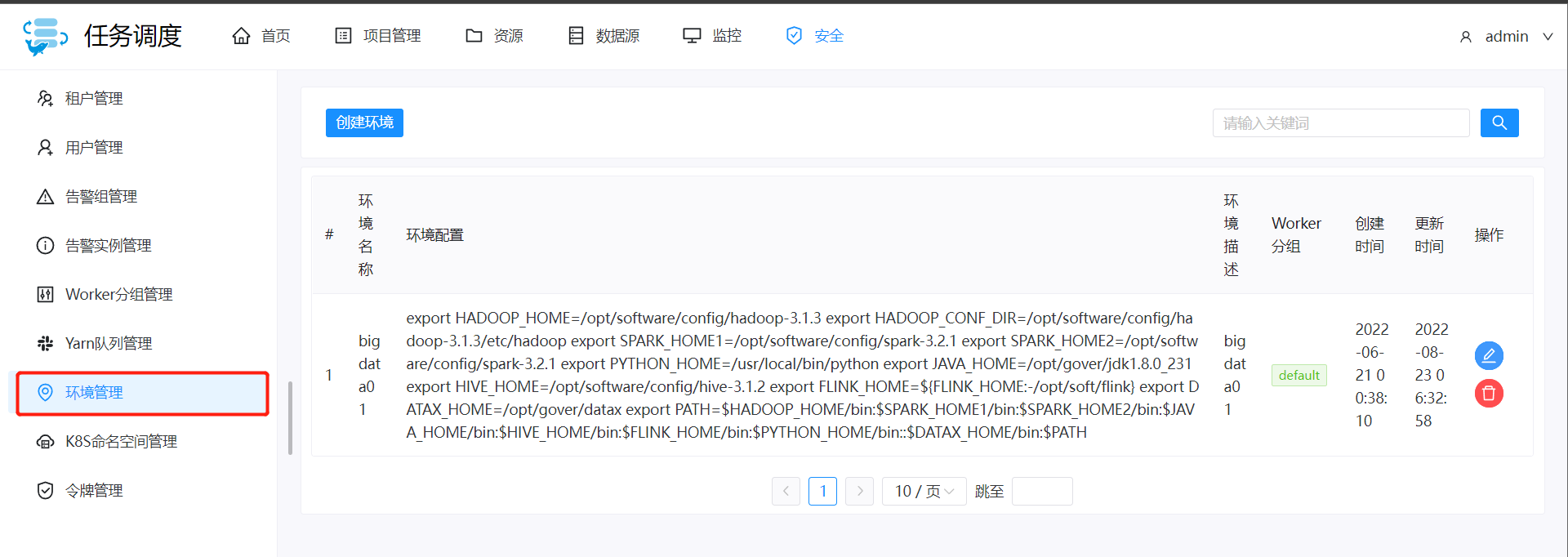
环境变量